Sample Audio File For Speech Recognition . Audio samples accompanying the paper melnet: It contains utterances of acted. Web the acted emotional speech dynamic database (aesdd) is a publicly available speech emotion recognition dataset. Web something went wrong and this page crashed! If the issue persists, it's likely a problem on our side. A generative model for audio in the frequency domain. Web individual samples of the ami dataset contain very large audio files (between 10 and 60 minutes), which are segmented to lengths feasible for training most speech. Web signalogic uses these wav files in speech recognition training, testing, and analysis work, for example comparing noise reduction and. Over 110 speech datasets are collected in.
from research.aimultiple.com
A generative model for audio in the frequency domain. If the issue persists, it's likely a problem on our side. Web signalogic uses these wav files in speech recognition training, testing, and analysis work, for example comparing noise reduction and. Audio samples accompanying the paper melnet: Web individual samples of the ami dataset contain very large audio files (between 10 and 60 minutes), which are segmented to lengths feasible for training most speech. Web the acted emotional speech dynamic database (aesdd) is a publicly available speech emotion recognition dataset. It contains utterances of acted. Web something went wrong and this page crashed! Over 110 speech datasets are collected in.
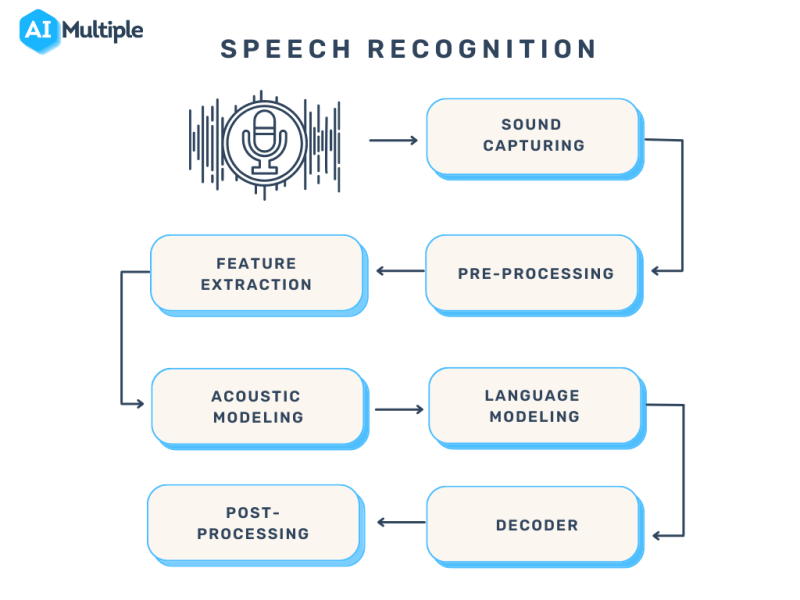
Speech Recognition Everything You Need to Know in 2023
Sample Audio File For Speech Recognition Over 110 speech datasets are collected in. Web something went wrong and this page crashed! Audio samples accompanying the paper melnet: Web signalogic uses these wav files in speech recognition training, testing, and analysis work, for example comparing noise reduction and. A generative model for audio in the frequency domain. If the issue persists, it's likely a problem on our side. Web the acted emotional speech dynamic database (aesdd) is a publicly available speech emotion recognition dataset. It contains utterances of acted. Over 110 speech datasets are collected in. Web individual samples of the ami dataset contain very large audio files (between 10 and 60 minutes), which are segmented to lengths feasible for training most speech.
From speechtext.ai
Speech Recognition API Speech Recognition Service Speech to Text API Sample Audio File For Speech Recognition Web something went wrong and this page crashed! Web signalogic uses these wav files in speech recognition training, testing, and analysis work, for example comparing noise reduction and. A generative model for audio in the frequency domain. Over 110 speech datasets are collected in. It contains utterances of acted. Web individual samples of the ami dataset contain very large audio. Sample Audio File For Speech Recognition.
From www.youtube.com
How Does Speech Recognition Work? Learn about Speech to Text, Voice Sample Audio File For Speech Recognition If the issue persists, it's likely a problem on our side. Web something went wrong and this page crashed! Audio samples accompanying the paper melnet: Web individual samples of the ami dataset contain very large audio files (between 10 and 60 minutes), which are segmented to lengths feasible for training most speech. Web signalogic uses these wav files in speech. Sample Audio File For Speech Recognition.
From www.shaip.com
Automatic Speech Recognition (ASR) Definition, Use Cases, Example Sample Audio File For Speech Recognition Over 110 speech datasets are collected in. Web the acted emotional speech dynamic database (aesdd) is a publicly available speech emotion recognition dataset. If the issue persists, it's likely a problem on our side. Audio samples accompanying the paper melnet: It contains utterances of acted. A generative model for audio in the frequency domain. Web something went wrong and this. Sample Audio File For Speech Recognition.
From farizfadian.blogspot.com
Python Speech Recognition using Microphone or Audio File Example Sample Audio File For Speech Recognition A generative model for audio in the frequency domain. Web the acted emotional speech dynamic database (aesdd) is a publicly available speech emotion recognition dataset. It contains utterances of acted. Web something went wrong and this page crashed! Web individual samples of the ami dataset contain very large audio files (between 10 and 60 minutes), which are segmented to lengths. Sample Audio File For Speech Recognition.
From pylessons.com
PyLessons Sample Audio File For Speech Recognition Web something went wrong and this page crashed! Web individual samples of the ami dataset contain very large audio files (between 10 and 60 minutes), which are segmented to lengths feasible for training most speech. If the issue persists, it's likely a problem on our side. It contains utterances of acted. Web the acted emotional speech dynamic database (aesdd) is. Sample Audio File For Speech Recognition.
From talkroute.com
Automatic Speech Recognition & Mixing it with IVR Sample Audio File For Speech Recognition If the issue persists, it's likely a problem on our side. A generative model for audio in the frequency domain. It contains utterances of acted. Web signalogic uses these wav files in speech recognition training, testing, and analysis work, for example comparing noise reduction and. Audio samples accompanying the paper melnet: Web something went wrong and this page crashed! Web. Sample Audio File For Speech Recognition.
From www.examples.com
Appreciation Speech 10+ Examples, Format, How to Prepare, PDF Sample Audio File For Speech Recognition Web something went wrong and this page crashed! Audio samples accompanying the paper melnet: Over 110 speech datasets are collected in. It contains utterances of acted. Web the acted emotional speech dynamic database (aesdd) is a publicly available speech emotion recognition dataset. Web signalogic uses these wav files in speech recognition training, testing, and analysis work, for example comparing noise. Sample Audio File For Speech Recognition.
From insights.daffodilsw.com
SpeechToText How Automatic Speech Recognition Works Sample Audio File For Speech Recognition Audio samples accompanying the paper melnet: A generative model for audio in the frequency domain. Web something went wrong and this page crashed! Over 110 speech datasets are collected in. It contains utterances of acted. Web signalogic uses these wav files in speech recognition training, testing, and analysis work, for example comparing noise reduction and. Web individual samples of the. Sample Audio File For Speech Recognition.
From www.clickworker.com
Audio Data Sets for Speech Recognition Training by real people Sample Audio File For Speech Recognition Audio samples accompanying the paper melnet: Web individual samples of the ami dataset contain very large audio files (between 10 and 60 minutes), which are segmented to lengths feasible for training most speech. A generative model for audio in the frequency domain. Web the acted emotional speech dynamic database (aesdd) is a publicly available speech emotion recognition dataset. It contains. Sample Audio File For Speech Recognition.
From www.narakeet.com
Create highquality text to speech audio Sample Audio File For Speech Recognition Over 110 speech datasets are collected in. Web individual samples of the ami dataset contain very large audio files (between 10 and 60 minutes), which are segmented to lengths feasible for training most speech. Audio samples accompanying the paper melnet: Web the acted emotional speech dynamic database (aesdd) is a publicly available speech emotion recognition dataset. It contains utterances of. Sample Audio File For Speech Recognition.
From medium.com
Speech recognition and voice commands for your site by Voxpow Voice Sample Audio File For Speech Recognition Web signalogic uses these wav files in speech recognition training, testing, and analysis work, for example comparing noise reduction and. Audio samples accompanying the paper melnet: A generative model for audio in the frequency domain. Web individual samples of the ami dataset contain very large audio files (between 10 and 60 minutes), which are segmented to lengths feasible for training. Sample Audio File For Speech Recognition.
From research.aimultiple.com
Speech Recognition Everything You Need to Know in 2023 Sample Audio File For Speech Recognition Web something went wrong and this page crashed! Over 110 speech datasets are collected in. If the issue persists, it's likely a problem on our side. It contains utterances of acted. A generative model for audio in the frequency domain. Web signalogic uses these wav files in speech recognition training, testing, and analysis work, for example comparing noise reduction and.. Sample Audio File For Speech Recognition.
From machinelearning.apple.com
Improved Speech Recognition for People Who Stutter Apple Machine Sample Audio File For Speech Recognition If the issue persists, it's likely a problem on our side. Over 110 speech datasets are collected in. Web something went wrong and this page crashed! It contains utterances of acted. Web individual samples of the ami dataset contain very large audio files (between 10 and 60 minutes), which are segmented to lengths feasible for training most speech. A generative. Sample Audio File For Speech Recognition.
From au.mathworks.com
Speaker Identification Using Pitch and MFCC MATLAB & Simulink Sample Audio File For Speech Recognition Over 110 speech datasets are collected in. Web signalogic uses these wav files in speech recognition training, testing, and analysis work, for example comparing noise reduction and. Audio samples accompanying the paper melnet: A generative model for audio in the frequency domain. Web the acted emotional speech dynamic database (aesdd) is a publicly available speech emotion recognition dataset. It contains. Sample Audio File For Speech Recognition.
From texte.rondi.club
Speech To Text From Audio File Texte Préféré Sample Audio File For Speech Recognition Over 110 speech datasets are collected in. Web signalogic uses these wav files in speech recognition training, testing, and analysis work, for example comparing noise reduction and. Web the acted emotional speech dynamic database (aesdd) is a publicly available speech emotion recognition dataset. Web something went wrong and this page crashed! A generative model for audio in the frequency domain.. Sample Audio File For Speech Recognition.
From www.examples.com
Speech For Employee Recognition Examples, Format, PDF, Tips Sample Audio File For Speech Recognition Web something went wrong and this page crashed! If the issue persists, it's likely a problem on our side. Over 110 speech datasets are collected in. Audio samples accompanying the paper melnet: It contains utterances of acted. Web individual samples of the ami dataset contain very large audio files (between 10 and 60 minutes), which are segmented to lengths feasible. Sample Audio File For Speech Recognition.
From www.youtube.com
Speech Recognition 5 Python Save Audio With The Speech Recognition Sample Audio File For Speech Recognition Web individual samples of the ami dataset contain very large audio files (between 10 and 60 minutes), which are segmented to lengths feasible for training most speech. Web the acted emotional speech dynamic database (aesdd) is a publicly available speech emotion recognition dataset. It contains utterances of acted. Audio samples accompanying the paper melnet: Over 110 speech datasets are collected. Sample Audio File For Speech Recognition.
From ccci.am
The Role of Audio and Speech Data in AI Voice Recognition CCC Sample Audio File For Speech Recognition Web the acted emotional speech dynamic database (aesdd) is a publicly available speech emotion recognition dataset. Audio samples accompanying the paper melnet: If the issue persists, it's likely a problem on our side. Web something went wrong and this page crashed! Web signalogic uses these wav files in speech recognition training, testing, and analysis work, for example comparing noise reduction. Sample Audio File For Speech Recognition.